俄方称已控制乌东战略重镇波◣克罗夫斯克附近█村庄
2024-08-27 05:23:34
URL: /4xercu/hjg/newshow/20240827_725827.shtml
8月24日消息,英伟达邀请部分媒体举办吹风会,向科技记者首次展示了Blackwell平台。英伟达将出席8月25-27日举办的HotChips2024活动,展示Blackwell平台在数据中心投入使用】的相关情况。


否认Blackwell推迟上市消息
英伟达在本次吹╳风会上,驳斥了Blackwell推迟上市的消息,并分享了更多数据中心Goliath的相关♂信息。

英伟达在吹风会上演示了Blackwell在其一个数据中心的运行情况,并强调Blackwell正〓在按计划推进,并将于今年晚些时候向客户发货。

有消息称Blackwell存在某种缺陷或问题,今年无法投放市场,这种说法是站不住脚的。
Blackwell简介
英伟达表示Blackwell不仅仅是一款芯片,它还是一个平@台。就像Hopper一样,Blackwell包含面〓向数据中心、云计算和人工智能客户的大量ξ 设计,每个Blackwell产品都由不同的芯片组成。

IT之家附上包括的芯片如◇下:
BlackwellGPU
GraceCPU
NVLINKSwitchChip
Bluefield-3
ConnectX-7
ConnectX-8
Spectrum-4
Quantum-3
Blackwell桥架
英伟达还分享了Blackwell系列产品中各种桥▓架的全新图片。这些是首次分享的Blackwell桥架图片,展示了设Ψ 计下一代数据中心平台所需的大量专业工程技术。




目标万亿参数AI模型
Blackwell旨在满足现代人工智能╱的需求,并为大型语言模∞型(如Meta的405BLlama-3.1)提供出色的ζ 性能。随着LLMs的规模越来越大,参数也』越来越多,数据中心将需要更多的计算和更低的延迟。
多GPU推理方法
多GPU推理︽方法是在多个GPU上进行计算∏,以获得低延迟和高吞吐量卐,但采用多GPU路线也有其复杂性。多GPU环境中的◣每个↑GPU都必须将计算结果发╲送给每一层的其他GPU,这就需要高带宽的GPU对GPU通信。

多GPU推理方№法是在多个GPU上进行计算,以获得低延迟和高吞吐量,但采用多GPU路线也有其复杂性。多GPU环境中的每个GPU都必须将计算结果发送给每一层的其他GPU,这就需要高带宽的GPU对GPU通信。
更快的NVLINK交换机
通过Blackwell,NVIDIA推出了速度更快的NVLINK交换机,将结构带宽提高了一倍,达到1.8TB/s。NVLINK交换机⊙本身是基于台积电4NP节点的800mm2芯片,可将NVLINK扩展到GB200NVL72机架中的72个GPU。


该芯片通过72个端①口提供7.2TB/s的全对全双向带宽,网内计算能力♀为3.6TFLOPs。NVLINK交换机托盘配有两个这样的交换机,提供高达14.4TB/s的总带宽。

水冷散热
英伟达采用水冷∴散热,来提升性〖能和效率。GB200、GraceBlackwellGB200和B200系统将采用这些新的液冷解决方案,可将数据中心设施的电力成本最多降低28%。


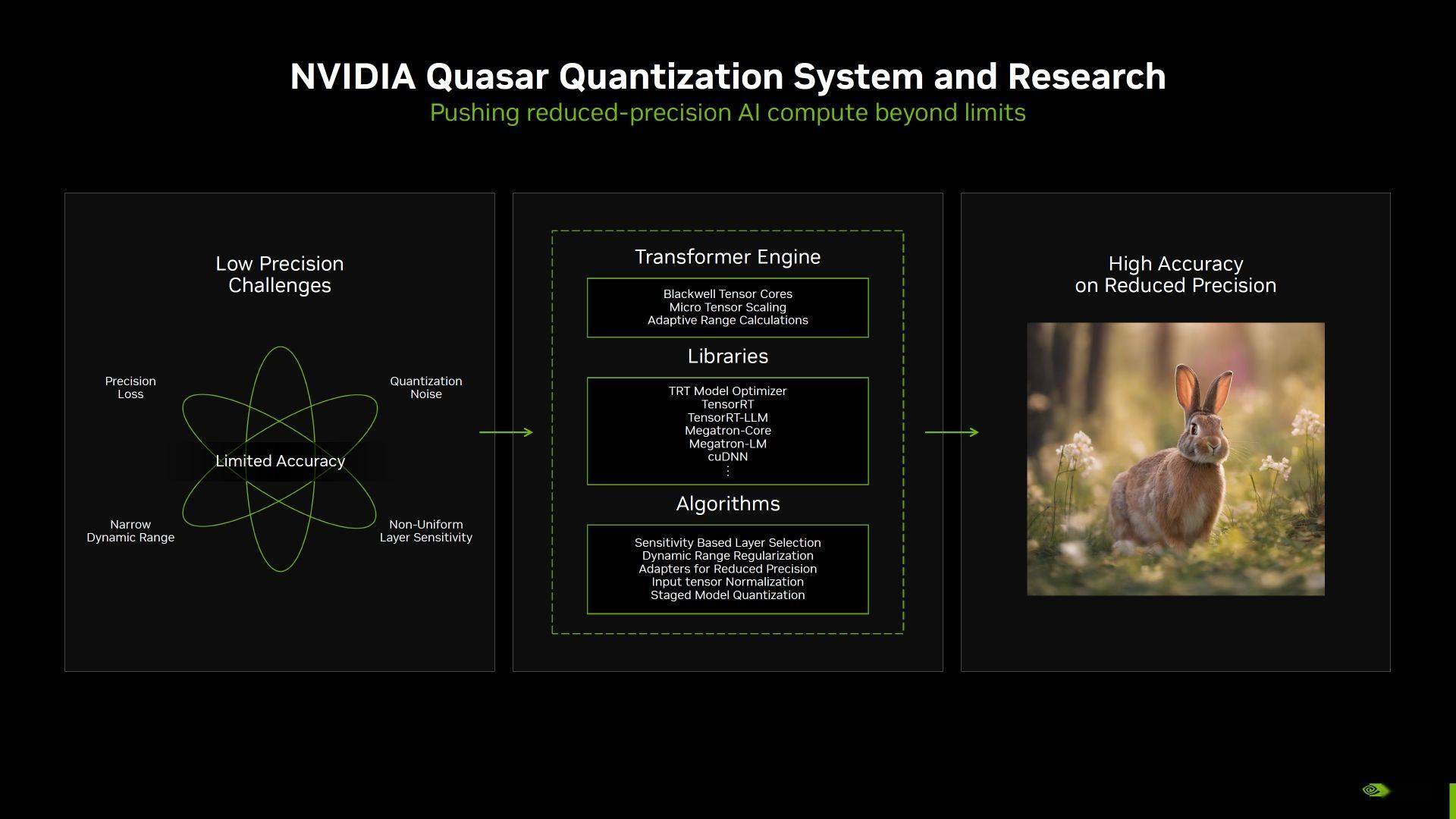
首张使用FP4计算⌒ 生成的人工智能图像
英伟达?(NVIDIA?)还分享了全球首张使用FP4计算生成的人工智能图像。图中显示,FP4量化模型生ω成的4位兔子图像与FP16模型非常♂相似,但速※度更快。

该图像由MLPerf在稳定扩散中使用Blackwell制作而成。现在,降低精度(从FP16到FP4)所面临的挑战是会损失一些精度】。