�����ա����״ξ���ȫ��������ϰ ���ʷ���
2024-08-27 05:22:44
URL: /4xercu/yydh/Mobile/20240827_640524.xhtml
���� ̫ԭ������ѧ�������ѧ�뼼��ѧԺ(������ѧ��Ժ)
ժҪ���ı������ǻ���ѧϰ�������ҪӦ��֮һ��ּ�ڽ��ı������Զ�����ΪԤ�����������ı����������У����õĻ���ѧϰ�㷨�������ر�Ҷ˹��֧��������(SVM)����������������ȡ���Щ�㷨ͨ���Ԩ��ı�����������ȡ(��TF-IDF����Ƕ���)�����ı�ת��Ϊ��ֵ�������������üලѧϰ�ķ�������ѵ����ͨ��ѵ����ģ���ܹ�ѧϰ�����ı�������ӳ���ϵ���Ӷ�ʵ�ֶ����ı����Զ����ࡣ��Щ�㷨�ڡ������ʼ�ʶ�����ŷ��ࡢ��з������������Ź㷺��Ӧ�á�
�ؼ��ʣ�TF-IDF������������������磻���ر�Ҷ˹
һ���Ш�����Ŀ��������
(һ)Ŀ�ĺ�Ҫ��
ʹ�ö��ֻ���ѧϰ�㷨�������ı�����ѧϰ����ʵ��ȷ���������ʼ�����ͨ�ʼ���
(��)�����
�Ѿ����������ݼ��������������ֺ�ѵ�����ͨw���Լ�����ʹ��sklearn�е����ر�Ҷ˹�㷨���������㷨������������㷨����ģ��ѵ���Ͳ��ԣ��õ�ʹ�ø���������ģ����ѧϰ���ߣ��Ƚϸ�����������ȱ������÷�Χ��
�������巽��
(һ)�㷨ʵ�ֵľ���ⷽ��
���û���ѧϰ����Ҫ�Ŀ⣬ͨ����������еĻ���ѧϰ�㷨�������ݼ����Ƚ��н�ѹ������ѹ����ɺ�Ҫ�����ݽ��д���������part1��part10�ļ��У������ļ������Ƿ���sp�������Ƿ��������ʼ��ı�ǩ�����������ݼ���ʹ��sklearn�е�������ѡȡ���ݣ�����20%��������Ϊ���Լ����������Ϊѵ������֮��ֱ�ʹ��sklearn�е����ر�Ҷ˹�㷨���������㷨������������㷨������ѵ����Ԥ�⣬����������ѧϰ�㷨�ļ��㾫�ȡ�F1ֵ����ȫ�ʵ�ָ������жԱȡ�
(��)��������
��������sklearn�����а��еĸ��ַ������������ر�Ҷ˹�㷨���������㷨������������㷨�ȣ������ַ����������������Ϊ��ͬ��ֵ���Ա������ݲ�ͬ�Է���������������ɵ�Ӱ�죬ͬʱ��֤��ʵ��Ŀ��ظ��ԺͿ���֤�ԣ����ɵ�����ط��������������г������������ڲ��Լ��Ϸֱ��Ӧ��ȫ�ʡ����ʡ�F1ֵ��ָ���Լ����ַ������Զ�Ӧ��ѧϰ���ߣ��Ա�����ַ��������ƺͲ������������
(��)����
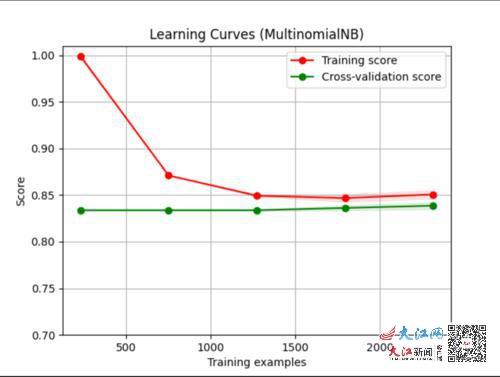
ͼ1.���ر�Ҷ˹ѧϰ����
ͼ1Ϊ���ر�Ҷ˹�㷨ѧϰ���ߣ���ɫ�ߴ������Լ�(ѧϰ������)��ȷ��(Score)����ɫ�ߴ�����ģ���ڲ��Լ��ϵ�ȷ�ʣ�������İ������Ŀ��ȴ�������(����ԽС��ģ���ȶ���Խ�ã���������Խ��)����ͼ1�ɿ���������ѵ����(Train examples)������ѵ������ȷ���½������Լ���ȷ������������ȶ���0.84���ң�ȷ��һ�㣬�������С�����н�ǿ�Ŀ������������
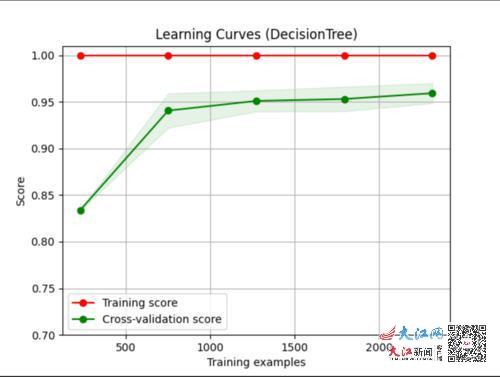
ͼ2.������
ͼ2Ϊ������ѧϰ���ߣ���ɫ�ߴ������Լ�(ѧϰ������)��ȷ��(Score)����ɫ�ߴ�����ģ���ڲ��Լ��ϵ�ȷ�ʣ�������İ������Ŀ��ȴ�������(����ԽС��ģ���ȶ���Խ�ã���������Խ��)����ͼ2�ɿ���������ѵ����(Train examples)������ѵ��������ȷ�ʻ������䣬���Լ���ȷ������������ȶ���0.96���ң�ȷ�ʸߣ�������ϴ��ڹ���Ϸ��մ�IJ��㡣
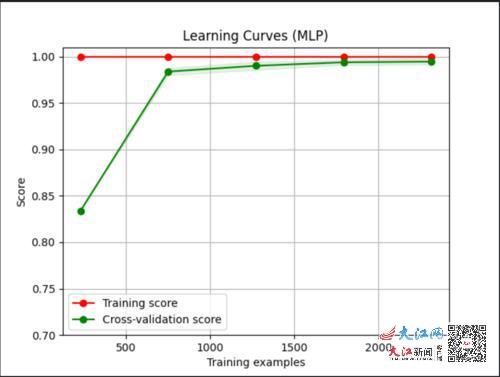
ͼ3.���������ѧϰ����
ͼ3Ϊ���ر�Ҷ˹�㷨ѧϰ���ߣ���ɫ�ߴ������Լ�(ѧϰ������)��ȷ��(Score)����ɫ�ߴ�����ģ���ڲ��Լ��ϵ�ȷ�ʣ�������İ������Ŀ��ȴ�������(����ԽС��ģ���ȶ���Խ�ã���������Խ��)����ͼ3�ɿ���������ѵ����(Train examples)������ѵ������ȷ�ʻ������䣬���Լ���ȷ������������ȶ���0.98���ң�ȷ�ʼ��ߣ��ҷ����С�������ȷ�ʸ��Լ������������ǿ���ŵ㡣
(��)����
��ʹ��TF-IDF��������������������ͨ���Ա����ر�Ҷ˹�㷨���������㷨�Ͷ���������㷨��ѧϰ���߿ɵó����½��ۣ�
1.���ر�Ҷ˹�㷨ȷ�ʲ��ߣ������׳��ֹ���ϵ���v�����㷨������ʱ��̣���Ӳ������Ҫ�ߣ��ʺ���ѵ�������ٻ�Ӳ���������������ʹ�á�
2.�������㷨ȷ�ʽϸߣ������������������㷨�����ڷ����������ϵ�ȱ�ݣ��Լ����Ӳ����һ��Ҫ���ʺ��ڲ����ڹ���Ϸ��յ������У��糵�ơ�ʶ����ɫʶ��ȵ�һʶ�����⣬���ʺ�������ʶ��
3.����������㷨����˼���ȷ���뼫����Ϸ��������ŵ㣬�����ַ����б������ŵģ����������Լ����Ӳ��Ҫ��ߣ��ʺ��ڸ߾��ȷ������⡣
�������������⼰�������
(һ)����
1.�ļ�·���������DATA_DIR�����е�·������ȷ��������Ŀ¼���ļ��ṹ������Ԥ�ڣ����ᵼ���ļ�������ȷ��ȡ��
2.�ı��ִʺ�ͣ�ôʡ�����Ӣ���ı���������Ҫ���Ƿִʺ�ͣ�ôʵ����⣬���账������Ӣ���ʼ���������Ҫ������Ӧ�Ĵ������衣
3.����������ÿ����������������������Ե�������Ҫͨ��ʵ����ȷ����ѵIJ������á�
(��)���
1.��ȷ���Դ������йر���Ŀ¼�IJ��֣���֤��©��
2.���ӱ�����Բ��ֵĹ��ܣ�ͨ������ĸ����ռ����һָ���ж���Ӣ�ģ�����Ӣ���Կո��š�����Ϊ�ָ�����
3.ͨ����������ʵ�����ݣ�ȷ������Ѳ�����Ϸ�Χ�������һ���ԡ�
�ġ����
��ȷ��Ŀ������ݽṹ�������Ŀ���Ǵ����ʼ������ݼ�����ʹ�ò�ͬ�ķ���������ѵ�������������ȣ���Ҫȷ�����������ݼ��Ľṹ��ʽ���Լ���ϣ�������ݼ�����ȡʲô��Ϣ�������������У��ʼ��ı�����ȡ��ת��ΪTF-IDF���������������ı������г�����Ԥ�������衣
Ԥ��������Ҫ�ԣ��ı�����ͨ����ҪԤ�������ܱ�����ѧϰģ�ơ�����Чʹ�á������������У�ʹ����TfidfVectorizer�����ı�ת��Ϊ��ֵ����������Ԥ�������軹�������Զ�ȡ�ļ�ʱ���ܳ��ֵı���������ͨ��errors='ignore'����ʵ�֡�
ģ��ѡ��Ͳ���������ѡ�������ֲ�ͬ�ķ�����(���ر�Ҷ˹���������Ͷ��������)���Ƚ����ǵ����ܡ�ÿ�ַ�������������ص��ŵ�����ó��������⣬���ڶ��������(MLP)�����������ز�Ĵ�С����������������ǿ�ȵȡ���������Ż�ģ�͵����ܡ�
��������Ҫ�ԣ���ѵ��ģ�ͺ�ʹ�ò��Լ�������ģ�͵�������������Ҫ�ġ����������˽�ģ����δ���������ϵı��֣�������ָ����һ����ģ��ѡ��Ͳ��������������������У�ʹ����ȷ�ʡ����౨���F1����������ָ�ꡣ
�����Ľ�������ѧϰ��һ�������Ĺ��̣�������Ҫ��γ��Բ�ͬ��ģ�ͺͲ������ò����ҵ���ѽ�����������⣬�����Կ���ʹ�ø����ӵ�������ȡ����������ѧϰ������������������һ��������ܡ�
�ο����ף�
[1]��ѩ.��Ҷ˹�Ż��������ʼ������е�Ӧ���о�.���ݹ���ѧԺѧ����(��Ȼ��ѧ��),2023 (02)
[2]������,��Ц.����Python���Ժ����ر�Ҷ˹�㷨�������ı���з����������ʵ��.�Ƽ�����,2024 ,16 (12).
[3]������.���ھ��������������ѡ��������������վ����С���.���մ�ѧ˶ʿ����,2020���07��.
[4]��¹.���ڱ�Ҷ˹����������ʼ����˼����о�.�Ϻ����̼�����ѧ˶ʿ����,2021���04��.
[5]�����������.����ѧϰ�������ʡ����������е�ʵ��.����֪ʶ�뼼��,2021 ,17 (08).
����飺
���ʣ��У�2004��10������������Ȫ�ˣ�̫ԭ������ѧ�������ѧ�뼼��ѧԺ(������ѧԺ)���о������˹����ܡ�






![[第30话] 秘密研究所(2) - 30 | 逃亡命中点|秘密研究所](https://img2.baidu.com/it/u=180770495,3055132168&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=889woywlzbzjpduunmibxyfamimtakyitqj)